Read the original article: On #DFIR Analysis
I wanted to take the opportunity to discuss DFIR analysis; when discussing #DFIR analysis, we have to ask the question, “what _is_ “analysis”?”
In most cases, what we call analysis is really just parsing some data source (or sources) and running keyword searches. This is not analysis…this is running keyword searches. Or, what we call “analysis” is really nothing more than running a set of tools and viewing the output. Again, this is not analysis.
We “do analysis” when we take in data sources, perhaps apply some parsing, and then apply our knowledge and experience to those data sources. This is pretty much how it’s worked since I got started in the field over 20 yrs ago, and I’ll admit, I was just following what I had seen being done before me. Very often, the “apply our knowledge and experience” has been abstracted through a commonly used commercial forensic analysis tool or framework (i.e., EnCase, X-Ways, FTK, Autopsy, to name a few…).
The process of collecting data from systems has been addressed by many at this point. There are a number of both free and commercially available tools for collecting information from systems.
Over time, some have worked to make the parsing and analysis process more efficient, by automating various aspects of the process, by either setting up processes via the commercial tools, or by using some external means. For example, looking way back in the mists of time when Chris “CPBeefcake” Pogue and I were working PCI engagements as part of the IBM ISS ERS team, we worked to automate (as much as possible) the various searches (hashes, files names, path names) required by Visa (at the time) so that they were done in as complete, accurate, and consistent manner as possible. Further, tools such as plaso provide a great deal of (albeit incomplete) parsing capability.
A common issue with both collection and parsing tools is not with the tools themselves, but how they’re viewed and used. The analysts using such tools very often do little to update or extend those tools, looking at the tools as the end of their involvement in the process, rather than the beginning.
So, while this automates some tasks, the actual analysis is still left to the experience and knowledge of the individual analyst, and for the most part, does not extend much beyond that. This includes not only what data sources and artifacts to look to, but also the context and meaning of those (and other) data sources and artifacts. However, as Jim Mattis stated in his book, “Call Sign Chaos“, “…your personal experiences alone are not broad enough to sustain you.” While this statement was made specifically within the context of a warfighter, the same thing is true for DFIR analysts. So, the question becomes, how can we implement something like this in DFIR, how do we broaden the scope of our own personal experiences, and build up the knowledge and experience of all analysts, across the board, in a consistent manner?
The answer is that, much like McChrystal’s “Team of Teams“, we need a new model.
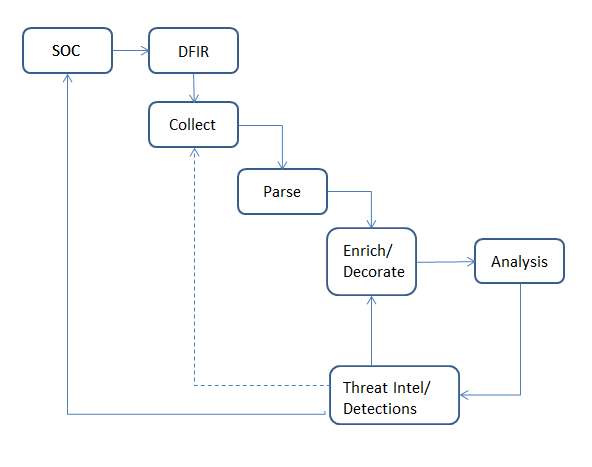 |
| Fig 1: Process Schematic |
A New DFIR Model
Back in the day…I love saying that, because I’m at the point in my career where I can…”DFIR” meant getting a call and going on-site to collect data, be it images, logs, triage data, etc.
As larger, more extensive incidents were recognized and became more commonplace, there was a shift in the industry to where some DFIR consulting firms were providing EDR tools to the customer to install, the telemetry for which reported back to a SOC. Initial triage and scoping could occur either prior to an analyst arriving on-site, or the entire engagement could be run, from a technical perspective, remotely.
Whether the engagement starts with a SOC alert, or with a customer calling for DFIR support and EDR being pushed out, at some point, data will need to be collected from a subset of systems for more extensive analysis. EDR telemetry alone does not provide all the visibility we need to respond to incidents, and as such, collecting triage data is a very valuable part of the overall process. Data is collected, parsed, and then “analyzed”. For the most part, there’s been a great deal of work in this area, including here, and here. The point is that there have been more than a few variations of tools to collect triage data from live Windows systems.
Where the DFIR industry, in the general sense, falls short in this process (see fig 1) is right around the “analysis” phase. This is due to the fact that, again, “analysis” consists of each analyst applying the sum total of their own knowledge and experience to the data sources (triage data collected from systems, log data, EDR telemetry, etc.).
Why does it “fall short”? Well, I’ll be the first to tell you, I don’t know everything. I’ve seen a lot of ransomware and targeted (“nation state”, “cybercrime”) threat actors during my time, but I haven’t seen all of them. Nor have I ever done a BEC engagement. Ever. I haven’t avoided them or turned them down, I’ve just never encountered one. This means that the analysis phase of the process is where things fall short.
So how do we fix that? One way is that if I take everything I learn…new findings, lessons learned, anything I find via open sources…and “bake it back into” the overall process via a feedback loop. Now, this is something that I’ve done partially through several tools that I use regularly, including RegRipper, eventmap.txt, etc. This way, I don’t have to rely on my fallible memory; instead, I add this new information to the automated process, so that when I parse data sources, I also “enrich” and “decorate” appropriate fields. I’m already automating the parsing so that I don’t miss something important, and now, I can increase visibility and context by automating the enrichment and decoration phase.
Now, imagine how powerful this would be if we took several steps. First, we make this available to all analysts on the team. What one analyst learns instantly becomes available to all analysts, as the experience and knowledge of one is shared with many. Steve learns something new, and it’s immediately available to David, Emily, Margo, and all of the other analysts. You do not have to wait until Steve works directly with Emily on an engagement, and you do not have to hope that the subject comes up. The great thing is that if you make this part of the DFIR culture, it works even if Steve goes on paternity leave or a family vacation, and it persists beyond any one analyst leaving the organization entirely.
Second, we further extend our enrichment and decoration capability by incorporating threat intelligence. If we do so initially using open reporting, we can greatly extend that open reporting by providing actual intrusion intelligence. We can use open reporting to take what others see on engagements that we have yet to experience, and use that to extend our own experience. Further, the threat intelligence produced (if that’s something you’re doing) now incorporates actual intrusion intel, which is tied directly to on-system artifacts. For example, while open reporting may state that a particular threat actor group “disables Windows Defender”, intrusion intel from those incidents will tell us how they do so, and when during the attack cycle they take these actions. This can provide insight into better tooling and visibility, earlier detection of threat actors, and a much more granular picture of what occurred on the system.
Third, because this is all tied to the SOC, we can further extend our capabilities by baking new DFIR findings back into the SOC in the form of detections. This feedback loop leads to higher fidelity detections that provide greater context to the SOC alerts themselves. A great example of this feedback process can be seen here; while this blog post just passed it’s 5th birthday, all that means is that the process worked then and is still equally, if not more, valid today. The use of WMI persistence led directly to the creation of new high-fidelity SOC EDR detections, which provided significantly greater efficacy and context.
While everyone else is talking about ‘big data’, or the ‘lack of cybersecurity skills’, there is a simple approach to addressing those issues, and more…all we need to do is change the business model used to drive DFIR, and change the DFIR culture.
Read the original article: On #DFIR Analysis