Read the original article: An Oxymoron : Static Analysis of a Dynamic Language (Part 5)
An Oxymoron : Static Analysis of a Dynamic Language (Part 5)
Overcoming challenges using Code Property Graphs
From the previous post we explored the idea of applying taint flow analysis upon an untyped and asynchronous event handling paradigm.
Representing Programs
We need an appropriate representation of programs to carry out static analysis. As we wish to do flow sensitive analysis, our representation must also reflect the order of the instructions. The source code of a program is then represented as a set of graphs, one for each function in the code. Since higher order functions are present we do not know statically which functions are invoked at a given call site and hence insertion of inter-procedural edges are left to the analysis. The nodes in the graph are basic blocks.
Each basic block represents a sequential set of instructions in the original program with several exit points (sinks) and one entry point (source).
When analyzing programs consisting of multiple functions one can do either inter-procedural or intra-procedural analysis. When applying intra-procedural analysis, flow is not propagated across function boundaries and all information that can be extracted will be local to the current function.
Propagating information across function invocations is inter-procedural analysis. As mentioned above, in JavaScript control and data-flow are interdependent so in the general case we do not know which function a given invocation will call before the analysis. Special inter-procedural edges are added during analysis as data-flow facts are discovered. For each discovered function a call edge and a return edge are added. Naively adding inter-procedural edges quickly leads to unacceptable loss of precision.
To combat infeasible flow and the imprecision, context sensitivity needs to be added. When context sensitivity is enabled, a finite number of contexts exists in the analysis. Each function is now analyzed in a context and different flows in different contexts are kept apart. JavaScript offers many possible choices of contexts. As an object oriented language, many functions are often associated with objects, strings, etc. As mentioned JavaScript lacks a formal semantics. This means that designing a sound analysis will always be a best effort enterprise, no proof of correctness can be given.
A traditional dense analysis propagates dataflow facts along the edges of the control-flow graph. A forwards analysis propagates dataflow facts from a control-flow graph node to its successors, whereas a backwards analysis propagates dataflow facts to its predecessors. Every program point, represented by a control-flow graph node, maintains an entire abstract state. Immutable data structures and clever algorithms can reduce some of the memory overhead of dense dataflow analysis, but these techniques are not always applicable nor sufficient, especially when dealing with dynamic languages.
Overcoming these challenges using Code Property Graphs
The code property graph is a concept based on a simple observation: there are many different graph representations of code, and patterns in code can often be expressed as patterns in these graphs. While these graph representations all represent the same code, some properties may be easier to express in one representation over another. So, why not merge representations to gain their joint power, and, while we are at it, express the resulting representation as a property graph, the native storage format of graph databases, enabling us to express patterns via graph-database queries.
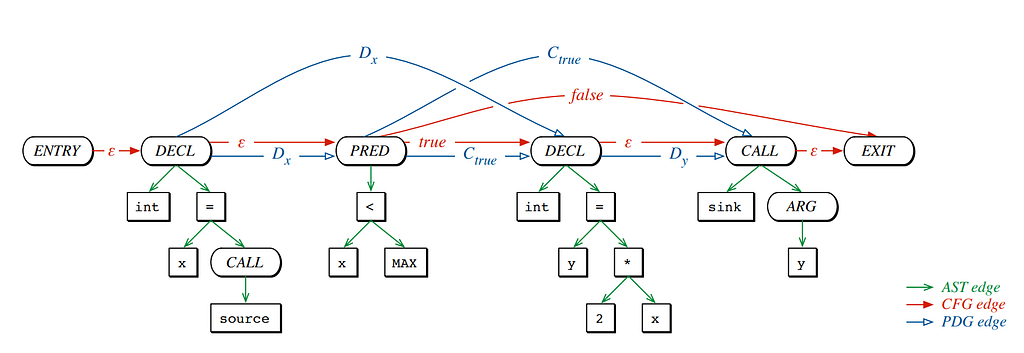
This original idea was published by Nico Golde, Daniel Arp, Konrad Rieck, and Fabian Yamaguchi at Security and Privacy in 2014, and extended for inter-procedural analysis one year later. The definition of the code property graph is very liberal, asking only for certain structures to be merged, while leaving the graph schema open. It is a presentation of a concept, data structure, along with basic algorithms for querying to uncover flaws in programs. It is assumed that somehow someone creates this graph for the target programming language. In consequence, concrete implementations of code property graphs differ substantially.
The code property graph enables us to efficiently switch between intra- and inter-procedural data flow analysis which gives precise context sensitive results. Those results improve the call graph which in turn improves the data flow tracking. Furthermore the code property graph enables us to create an adhoc approximated type system which greatly reduces the amount of individual call site resolutions and is thus key to analyze ECMASCRIPT complaint code in a reasonable amount of time.
Let us analyze an educational Node.js web application intentionally vulnerable to the OWASP Top 10 risks.
A notebook style threat modeling recipes are specified in this tutorial below
ShiftLeft is an application security platform built over the foundational Code Property Graph that is uniquely positioned to deliver a specification model to query for vulnerable conditions, business logic flaws and insider attacks that might exist in your application’s codebase.
If you’d like to learn more about ShiftLeft, please request a demo.
An Oxymoron : Static Analysis of a Dynamic Language (Part 5) was originally published in ShiftLeft Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
The post An Oxymoron : Static Analysis of a Dynamic Language (Part 5) appeared first on Security Boulevard.
Read the original article: An Oxymoron : Static Analysis of a Dynamic Language (Part 5)